

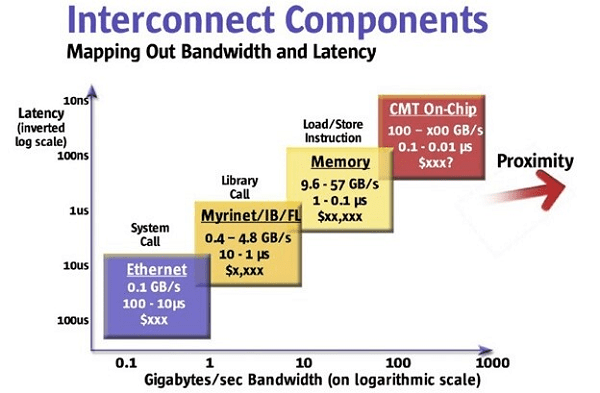
Jack Dongarra’s comments at SC22 on low efficiency of leadership-class supercomputers highlighted by latest High Performance Conjugate Gradients (HPCG) benchmark results will, I believe, influence the next generation of supercomputer architectures to optimize for sparse matrix computations. The upcoming technology that will help address this problem is CXL.0 switches to connect processing nodes, pooled memory and I/O resources into very large, coherent fabrics within a rack. I call this a “Petalith” architecture, and I think CXL will play a significant and growing role in shaping this emerging development in the high performance interconnect space. Fugaku is positioned as the first of a mainstream mainstream system I have always been particularly interested. . . .
[su_button url=’https://insidehpc.com/2022/12/sc22-cxl3-0-the-future-of-hpc-interconnects-and-frontier-vs-fugaku/’ target=’_blank’ style=’ghost’ background=’#010066′ color=’#010066′ size=’2′ wide=’no’ center=’no’ radius=’auto’]Read more at insidehpc.com[/su_button]

 By
By
 By
By
 By
By


 By
By
 By
By
 By
By







