The Dawn of Explainable AI Retrieval: Google’s Web Guide and the Shifting Search Landscape
Google’s latest experiment, “Web Guide,” may appear at first glance as a mere tweak to its familiar search interface. Yet beneath the surface, it signals a profound recalibration of the company’s approach to AI-powered information retrieval—a move that could reshape the very architecture of the web’s knowledge economy.
From Opaque Overviews to Transparent Clusters: A Strategic Pivot
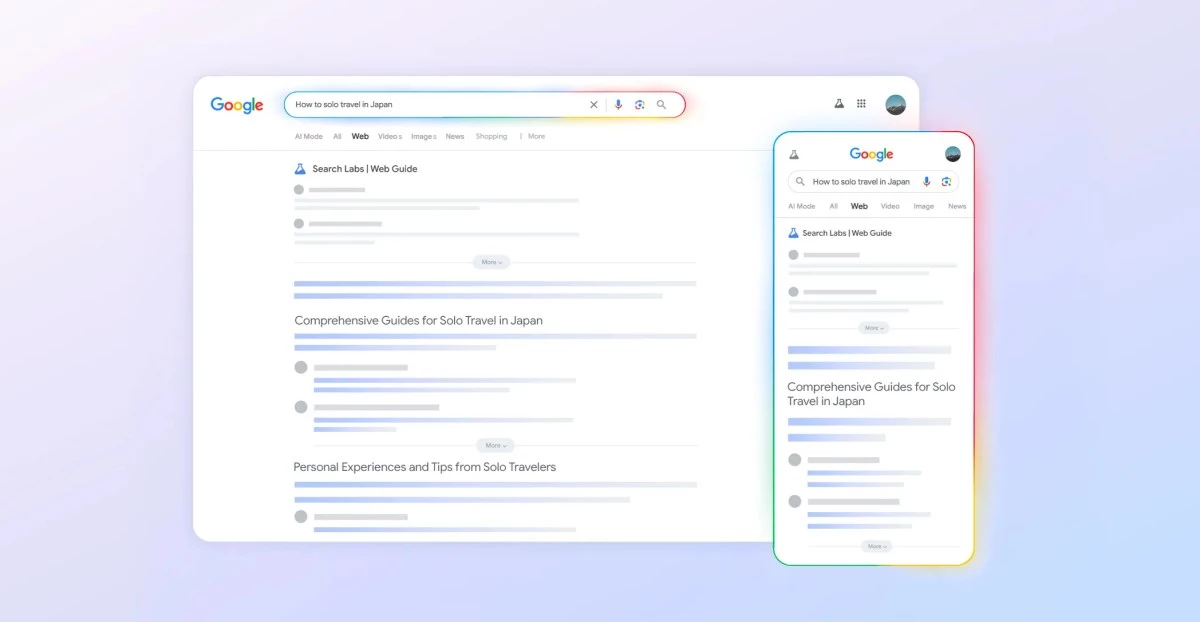
For years, Google’s march toward generative AI answers—epitomized by its Gemini-powered Overviews—has drawn both awe and ire. Critics, from publishers to policymakers, have warned that AI-generated summaries risk siphoning traffic away from the creators of original content, eroding the incentives that underpin the open web. In response, Web Guide emerges as a deft counterbalance: an opt-in experiment that algorithmically clusters search results, surfaces canonical links, and offers micro-summaries tied to specific URLs, all before any AI Overview appears.
This is more than a UI refresh. By restoring the prominence of human-authored pages and foregrounding attributed sources, Google is not only appeasing regulatory scrutiny—it is also acknowledging the competitive pressure from a new breed of search challengers. Platforms like Perplexity, Arc Search, and Microsoft’s Copilot have built their reputations on transparent, source-centric answers. Web Guide, with its layered categorization and explicit citations, mirrors this ethos, signaling that the future of search may hinge as much on trust and explainability as on raw generative power.
The Technical Backbone: Modular AI and Constrained Generation
At the heart of Web Guide lies a sophisticated interplay of AI techniques. Gemini, Google’s flagship large language model, parses each user query into a constellation of sub-questions, running them in parallel and reorganizing the results into what engineers call a “latent topical ontology.” Each category label is more than a convenience—it is a machine-learned map of the web’s semantic terrain, offering users a structured path through the informational thicket.
Crucially, Web Guide employs a lightweight retrieval-augmented generation (RAG) pipeline. Rather than spinning out full-length, potentially hallucinatory answers, the system generates concise micro-summaries tethered directly to their source URLs. This approach not only reduces the risk of factual error but also slashes the computational burden per query—a subtle yet significant nod to the realities of scaling AI responsibly.
Google’s decision to confine Web Guide to the Labs environment and the “Web” tab reflects a cautious, governance-first mindset. By limiting exposure, the company can monitor user behavior, assess legal risks, and fine-tune ad performance before contemplating a broader rollout to the main “All” tab. This iterative, data-driven deployment strategy is emblematic of Google’s broader philosophy: experiment boldly, but scale only when the economic and regulatory calculus is favorable.
Economic Stakes and the New Rules of Search Visibility
The implications for Google’s core business are profound. By prioritizing links and preserving on-page ad inventory, Web Guide helps safeguard the $175 billion advertising engine that powers the company. At the same time, every opt-in interaction generates a trove of high-quality, labeled data—fuel for further fine-tuning Gemini’s retrieval capabilities and fortifying Google’s data moat against upstart LLM providers.
For publishers and digital product leaders, the stakes are equally high. Web Guide’s algorithmic categories act as new gatekeepers, funneling traffic toward domains deemed “authoritative” by Gemini’s evolving taxonomy. As the paradigm shifts from keyword optimization to semantic structuring, those who invest in rich metadata, schema.org markup, and trustworthy signals will find themselves disproportionately favored in the new search hierarchy. The rise of content atomization—breaking knowledge into machine-readable, embeddable snippets—will become not just best practice, but a prerequisite for visibility.
Meanwhile, enterprise technology executives and policy risk officers must grapple with a fast-changing landscape. The cluster-and-cite model offers a template for internal search and knowledge management, promising greater transparency and compliance. But it also foreshadows a world in which regulatory standards around attribution, fair use, and remuneration are not just aspirational, but enforceable.
The Road Ahead: Search as a Copilot, Not a Gatekeeper
Web Guide is less a revolution than a recalibration—a strategic hedge that preserves Google’s economic interests, mollifies regulators, and lays the groundwork for a more explainable, source-centric search experience. As the competitive front shifts from black-box answers to transparent, AI-augmented retrieval, enterprises and publishers alike must adapt, reimagining their content for a world where semantic structure and trustworthiness are the new currency of visibility.
In this emerging landscape, the winners will be those who embrace the logic of the cluster: organizing knowledge not just for human readers, but for the AI copilots that increasingly mediate our access to information. The web’s next chapter, it seems, will be written not just by those who create content, but by those who teach machines how to find—and explain—it.

 By
By
 By
By
 By
By
 By
By

 By
By

 By
By